3D scene representations have gained immense popularity in recent years. Methods that use Neural Radiance fields are versatile for traditional tasks such as novel view synthesis. In recent times, some work has emerged that aims to extend the functionality of NeRF beyond view synthesis, for semantically aware tasks such as editing and segmentation using 3D feature field distillation from 2D foundation models. However, these methods have two major limitations: (a) they are limited by the rendering speed of NeRF pipelines, and (b) implicitly represented feature fields suffer from continuity artifacts reducing feature quality. Recently, 3D Gaussian Splatting has shown state-of-the-art performance on real-time radiance field rendering. In this work, we go one step further: in addition to radiance field rendering, we enable 3D Gaussian splatting on arbitrary-dimension semantic features via 2D foundation model distillation. This translation is not straightforward: naively incorporating feature fields in the 3DGS framework encounters significant challenges, notably the disparities in spatial resolution and channel consistency between RGB images and feature maps. We propose architectural and training changes to efficiently avert this problem. Our proposed method is general, and our experiments showcase novel view semantic segmentation, language-guided editing and segment anything through learning feature fields from state-of-the-art 2D foundation models such as SAM and CLIP-LSeg. Across experiments, our distillation method is able to provide comparable or better results, while being significantly faster to both train and render. Additionally, to the best of our knowledge, we are the first method to enable point and bounding-box prompting for radiance field manipulation, by leveraging the SAM model.
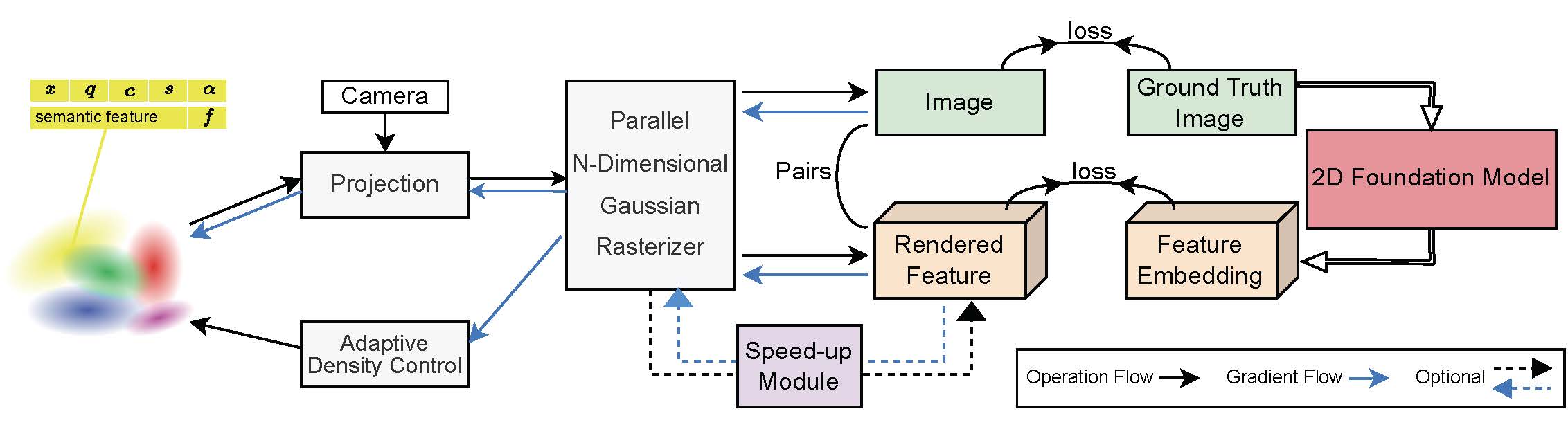
We adopt the same 3D Gaussian initialization from sparse SfM point clouds as utilized in 3DGS,
with the addition of an essential attribute: the semantic feature. Our primary innovation lies in the development
of a Parallel N-dimensional Gaussian Rasterizer, complemented by a convolutional speed-up module as an optional branch.
This configuration is adept at rapidly rendering arbitrarily high-dimensional features without sacrificing downstream performance.
Feature 3DGS empowers pixel-wise semantic scene understanding from any novel view, even with unseen labels, by mapping semantically
close labels to similar regions in the embedding space of 2D foundation models.




Experience sync issues with the GIFs? Simply refresh the webpage to synchronize playback.
The nature of explicit scene representation, coupled with feature fields, enables precise geometry and appearance editing
in 3D for any real-world scene prompted by natural language.







Experience sync issues with the GIFs? Simply refresh the webpage to synchronize playback.
To segment anything in a 3D scene, a few training view images is all you need.
We seamlessly integrate the latest computer vision foundation model, Segment Anything Model (SAM),
into the novel view synthesis pipeline through feature field distillation. This integration enables swift and precise
responses without invoking the original SAM workflow.
@inproceedings{zhou2024feature,
title={Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields},
author={Zhou, Shijie and Chang, Haoran and Jiang, Sicheng and Fan, Zhiwen and Zhu, Zehao and Xu, Dejia and Chari, Pradyumna and You, Suya and Wang, Zhangyang and Kadambi, Achuta},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={21676--21685},
year={2024}
}


